|
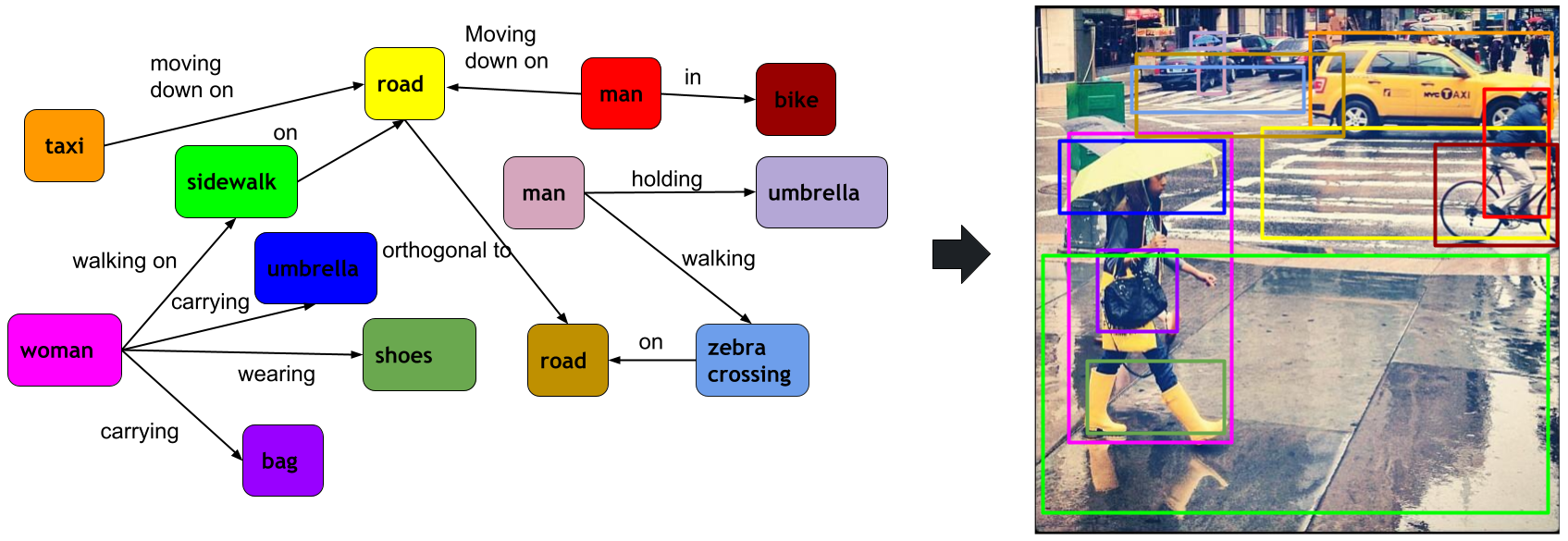
| Goal: Given a scene graph and an image, we ground (or localize) objects and, thereby, indirectly visual relationships as well jointly on the image. |
|
|
|
|
|
|
|
|
|
| Goal: Given a scene graph and an image, we ground (or localize) objects and, thereby, indirectly visual relationships as well jointly on the image. |
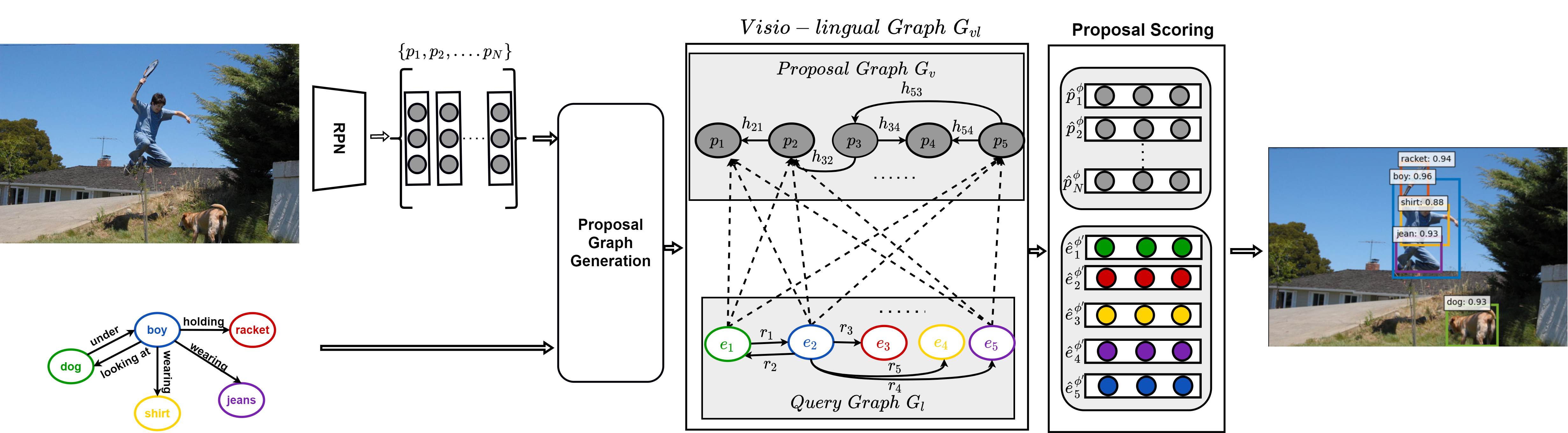
| This paper presents a framework for jointly grounding objects that follow certain semantic relationship constraints given in a scene graph. A typical natural scene contains several objects, often exhibiting visual relationships of varied complexities between them. These inter-object relationships provide strong contextual cues towards improving grounding performance compared to a traditional object query only-based localization task. A scene graph is an efficient and structured way to represent all the objects in the image and their semantic relationships. In an attempt towards bridging these two modalities representing scenes and utilizing contextual information for improving the object localization, we rigorously study the problem of grounding scene graphs in natural images. To this end, we propose a novel graph neural network-based approach referred to as Visio-Lingual Message Passing Graph Neural Network (VL-MPAGNet). The model first constructs a directed graph with object proposals as nodes and an edge between a pair of nodes representing a plausible relation between them. Then a three-step inter-graph and intra-graph message passing are performed to learn the context-dependent representation of the proposals and query objects. These object representations are used to score the proposals to generate object localization. The proposed method significantly outperforms the baselines on four public datasets. |
|
| The proposed scene-graph grounding framework (VL-MPAGNet) works in the following steps: (i) Proposal graph generation: A proposal graph is first constructed using object proposals obtained from RPN as nodes (shown using gray nodes), and edges defined using the relations present in the query. Directed edges from the query nodes to the proposals nodes (shown using dotted arrows) are also included to connect the query and proposal graph. (ii) Structured graph learning: Here, structured representation of proposals and queries are learned by a three-step message passing using edges from the query nodes to the proposals, and in the query and the proposal graphs independently, and (iii) Proposal scoring the object proposals are finally scored against the query nodes to localize objects. |
 |
A. Tripathi, A. Mishra, A. Chakraborty. Grounding Scene Graphs on Natural Images via Visio-Lingual Message Passing In WACV, 2023. (hosted on ArXiv) |
|
|